MapleJuice
MapleJuice is a batch processing system that works like MapReduce.
Overview
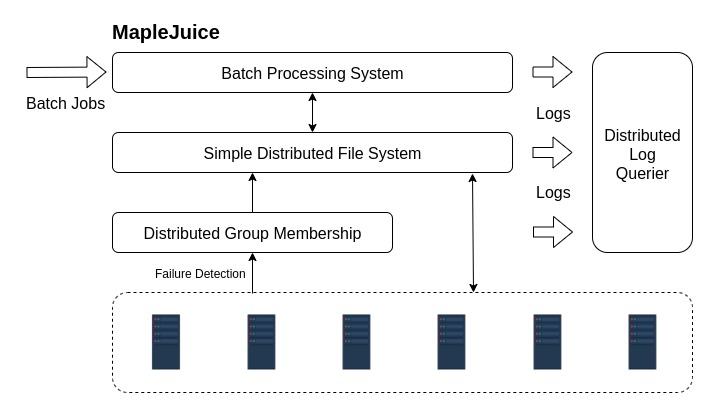
For detailed design of MapleJuice’s components, see:
- MapleJuice
- Simple Distributed File System
- Distributed Group Membership Service
- Distributed Log Querier
You can also check out our report.
Requirement
The code is developed and tested with Go v1.13. The only third party library used is emirpasic/gods v1.12.0 for treemap.
Usage
Run
go run main.go <port_number>
This will print log in a log file (vm.log). To print log to screen, use
go run main.go <port_number> --log2screen
Port numbers 1234, 1235 and 1236 are pre-occupied by and hence not allowed to be used.
A list of potential introducer’s addresses should be provided in the file introducer.config.
We also implemented a distributed log querier for debugging. You can check it out here.
You are then able to input commands to the terminal.
Group Membership
An introducer needs to be started first by entering
introducer
join
Other nodes can join subsequently by entering
join
After joining the group, the following commands are avaiable:
leave: leave the group
ml: print current node's membership list
id: print current node's id
The membership list includes a list of member ids, the member id is the concatenation of the member’s IP address, port number, and join time in string format.
Distributed File System
A node joins the DFS service as soon as it joins the group. The following commands are supported:
put <localfilename> <sdfsfilename>: put localfilename on local FS to sdfefilename on SDFS
get <sdfsfilename> <localfilename>: get sdfsfilename on SDFS to localfilename on local FS
delete <sdfsfilename>: delete sdfefilename on SDFS
ls <sdfsfilename>: list the storing nodes of all replicas of sdfefilename
store: list the SDFS files stored on the current node
MapleJuice
To start the MapleJuice service, you first need to let nodes join the group, and then select a node as the master node by entering
master
and others as the worker node by entering
worker
MapleJuice is invoked via two command lines. Overall a MapleJuice job takes as input a corpus of SDFS files and outputs a single SDFS file. At most one job can be processed at the same time, but multiple jobs can be submitted and queued meanwhile. Two example of applications (wordcount, URL access percentage) can be found here.
Maple
maple <maple_exe> <num_maples>
<sdfs_intermediate_filename_prefix> <sdfs_src_files>
The first parameter maple_exe is a user-specified executable that takes as input one file and outputs a series of (key, value) pairs. maple_exe is the SDFS file name. The second parameter num_maples specifies the number of Maple tasks. The last series of parameters (sdfs_src_files) specifies the location of the input files.
The output of the Maple phase (not task) is a series of SDFS files, one per key. That is, for a key K, all (K, any_value) pairs output by any Maple task must be appended to the file sdfs_intermediate_filename_prefix_K. After the Juice phase is done, you will have the option to delete these intermediate files.
Juice
juice <juice_exe> <num_juices>
<sdfs_intermediate_filename_prefix> <sdfs_dest_filename>
<delete_input={0,1}> [partitioner={range, hash}](optional, default=range)
The first parameter juice_exe is a user-specified executable that takes as input multiple (key, value) input lines, processes groups of (key, any_values) input lines together (sharing the same key, just like Reduce), and outputs (key, value) pairs. juice_exe is the SDFS file name. The second parameter num_juices specifies the number of Juice tasks.
Each juice task is responsible for a portion of the keys – each key is allotted to exactly one Juice task (this is done by the Master server). The juice task fetches the relevant SDFS files sdfs_intermediate_filename_prefix_K’s, processes the input lines in them, and appends all its output to sdfs_dest_filename sorted by key.
When the last parameter delete_input is set to 1, the MapleJuice engine deletes the input files automatically after the Juice phase is done. If delete_input is set to 0, the Juice input files is left untouched.